Künstliche Intelligenz (KI)
Andere Schreibweise: artificial intelligence (AI)
(erstellt: Februar 2022)
Permanenter Link zum Artikel: https://bibelwissenschaft.de/stichwort/201052/
Digital Object Identifier: https://doi.org/10.23768/wirelex.Knstliche_Intelligenz_KI.201052
1. Der Begriff der künstlichen Intelligenz
Um den Begriff der künstlichen Intelligenz näher zu bestimmen, muss geklärt werden, was mit dem Begriff der Künstlichkeit und mit dem Begriff der Intelligenz gemeint ist.
Der Begriff der Künstlichkeit wird in der KI-Debatte dem Begriff der Natürlichkeit gegenübergestellt. Während der Begriff der Natürlichkeit dasjenige bezeichnet, das unabhängig von der Existenz des Menschen zum ontologischen Inventar des Universums gehört und in verschiedene natürliche Arten (natural kinds) unterteilt ist, nimmt der Begriff der Künstlichkeit primär Bezug auf die Produkte menschlicher Kunstfertigkeit. Produkte menschlicher Kunstfertigkeit sind das Ergebnis intentionalen und zielgerichteten Handelns des Menschen in der Welt, das auf einem durch die menschliche Vernunft in ihrem theoretischen und praktischen Gebrauch geleiteten Umgang mit der Welt aufbaut. Der Bereich des so verstandenen Künstlichen umfasst daher alle Artefakte, die der Mensch (oder andere bewusste Lebewesen) aufgrund seines theoretischen und praktischen Wissens über die Welt konstruiert, so dass gilt: x ist künstlich genau dann, wenn x kein Exemplar einer natürlichen Art ist und das Produkt intentionalen und zielgerichteten (menschlichen) Handelns in der Welt ist (Göcke, 2020).
Der Begriff der Intelligenz ist schwierig zu definieren, da er umgangssprachlich auf einen inhomogenen Phänomenbereich Bezug nimmt und sich diverse Formen der Intelligenz voneinander unterscheiden lassen: “[T]here’s no agreement on what intelligence is even among intelligent intelligence researchers! So there’s clearly no undisputed ‘correct’ definition of intelligence. Instead, there are many competing ones, including capacity for logic, understanding, planning, emotional knowledge, self-awareness, creativity, problem solving and learning” (Tegmark, 2016, 49; siehe auch Hutter, 2016, 208f.; Legg/Hutter, 2007; Chalmers, 2016, 26f.). Wegen der Schwierigkeiten, den Intelligenzbegriff auf eine allgemeinverbindliche Art und Weise zu definieren, die dem gesamten Phänomenbereich adäquat ist, stützt sich die Forschung im Bereich der Künstlichen Intelligenz überwiegend auf einen spezifisch kognitiven Ansatz, der Intelligenz als dispositionale Eigenschaft versteht, die es ihrem Träger ermöglicht, aufgrund seiner inneren Struktur auf einen Input zur Erfüllung eines wohldefinierten Zwecks mit einem Output zu reagieren. Die Art und Weise der Reaktion muss sich dabei als in ihrem jeweiligen Kontext rationale Reaktion beschreiben lassen, die durch Verfahren deduktiven, induktiven und abduktiven Schließens geleitet wird und geeignet ist, den Zweck möglichst effizient zu erfüllen. Da die Fähigkeit, einen Zweck unter Zuhilfenahme deduktiver, induktiver und abduktiver Schlussverfahren zu erfüllen, die Fähigkeit ist, Probleme effizient zu lösen, führt das kognitive Verständnis des Intelligenzbegriffs dazu, Intelligenz als die Fähigkeit zu effizientem Problemlösen zu verstehen. Ein System ist also genau dann intelligent, wenn sein Verhalten unter Verwendung deduktiver, induktiver und abduktiver Schlussregeln in der Lage ist, ein Problem effizient zu lösen. „Ein System heißt intelligent, wenn es selbstständig und effizient Probleme lösen kann. Der Grad der Intelligenz hängt vom Grad der Selbstständigkeit, dem Grad der Komplexität des Problems und dem Grad der Effizienz des Problemlösungsverfahrens ab“ (Mainzer, 2016, 3; siehe auch Schmidhuber, 2016, 228).
Die skizzierten Definitionen von Künstlichkeit und Intelligenz ermöglichen es, den Begriff der künstlichen Intelligenz rudimentär zu spezifizieren: Ein System ist eine künstliche Intelligenz genau dann, wenn es zu keiner natürlichen Art gehört, sondern das Produkt intentionalen und zielgerichteten menschlichen Handelns in der Welt ist und es in der Lage ist, aufgrund seiner inneren Struktur mithilfe deduktiver, induktiver und abduktiver Schlussregeln seinen Zweck effizient zu erfüllen und somit Probleme effizient lösen kann: „Artificial Intelligence (AI) is sometimes defined as the study of how to build and/or program computers to enable them to do the sorts of things that minds can do. Some of these things are commonly regarded as requiring intelligence: offering a medical diagnosis and/or prescriptions, giving legal or scientific advice, proving theorems in logic or mathematics“ (Boden, 2005, 1) (siehe auch → Abduktion
Obwohl es naheliegend ist, dass die menschliche Intelligenz als biologisch verwirklichtes und evolutionär entwickeltes Vermögen zu effizientem Problemlösen ein paradigmatisches Beispiel für die Struktur und Verwirklichung von Intelligenz ist, käme es einem Fehlschluss gleich, daraus zu schließen, dass künstliche Formen der Intelligenz dem menschlichen Beispiel notwendigerweise ähneln müssen: „AIs could be – indeed, it is very likely that most will be – extremely alien. We should expect that they will have very different cognitive architectures than biological intelligences, and in their early stages of development they will have very different profiles of cognitive strengths and weaknesses” (Bostrom, 2014, 29).
2. Formen künstlicher Intelligenz
Obwohl der Wunsch des Menschen, künstliche Intelligenzen zu erschaffen, also durch sein eigenes technisches Geschick etwas zu konstruieren, das sich intelligent in der Welt verhält und in ihr eigenständig Probleme lösen kann, sich bereits in großen Teilen der frühen Kulturgeschichte der Menschheit nachweisen lässt (Brand, 2018, 12-18; Herrick, 2017, 12-23), hat die Entwicklung künstlicher Intelligenz erst seit der Mitte des vergangenen Jahrhunderts mit der Entwicklung der ersten Computer und damit der elektronischen Datenverarbeitung enorme Fortschritte erzielt: „There are strong links between the development of computers and the emergence of AI“ (Warwick, 2012, 2; Specht, 2019, 25-34). Trotz wesentlicher Vorarbeiten von Alan Turing zu Fragen der maschinellen Intelligenz und zu Methoden, wie die Intelligenz von Maschinen überprüft werden kann (Turing-Test; Turing, 1950), wird die offizielle Geburtsstunde der modernen KI-Forschung häufig auf das Jahr 1956 datiert, da in diesem Jahr der Begriff artificial intelligence offiziell zum ersten Mal in einem Antrag für eine Fachtagung von zehn Experten der Informatik und Kybernetik in Dartmouth (Hanover, New Hampshire) verwendet worden ist, die sich zum Ziel gesetzt hatte, zu untersuchen, „how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves“ (Russell/Norvig, 2016, 17).
Computer als Systeme elektronischer Datenverarbeitung sind ingenieurstechnisch konstruierte Annäherungen an Turing-Maschinen. Der Begriff der Turing-Maschine bezeichnet ein abstraktes mathematisches System, das sich in einem bestimmten Zustand befindet und auf einen eindeutigen formalen Input in der Form eines Symbols mit der Ausgabe eines eindeutigen formalen Outputs in der Form eines Symbols reagiert und daraufhin in einen neuen Zustand wechselt und auf den nächsten Input mit einem neuen Output reagieren kann. Der spezifische Output wird dabei durch die in der mathematischen Beschreibung der Turing-Maschine spezifizierte Funktion der Symbolzuordnung determiniert, die auch als der jeweilige Maschinenalgorithmus oder als das Programm der Maschine bezeichnet wird.
Bildlich kann man sich eine Turing-Maschine als ein Gerät vorstellen, das aus einem Schreib-/Lesekopf besteht, der auf ein diskretes Feld eines prinzipiell unendlichen Laufbandes gerichtet ist, auf dem eines oder keines einer endlichen Menge an Symbolen geschrieben stehen kann. Nachdem der Lesekopf registriert hat, welches Symbol auf dem Feld geschrieben wird, kommt die sogenannte Maschinentafel ins Spiel. Die Maschinentafel spezifiziert den jeweiligen Algorithmus, der festlegt, wie die Maschine auf welches Symbol mit welchem Output zu reagieren hat: Die Turing-Maschine kann das Symbol auf dem Feld durch ein anderes Symbol eines endlichen Alphabets ersetzen, das Symbol auf dem Feld löschen oder das Symbol unverändert lassen. Nachdem die Turing-Maschine auf eine der genannten Weisen reagiert hat, fährt der Schreib-/Lesekopf je nach in der Maschinentafel spezifizierten Anweisung eine Einheit auf dem Band nach rechts, links oder bleibt unverändert:
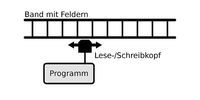
Eine zentrale These in Bezug auf die Leistungsfähigkeit von Turing-Maschinen ist die Church-Turing-These. Diese besagt, dass alles, was intuitiv von einem Menschen berechnet werden kann, auch von einer Turing-Maschine berechnet werden kann. Obwohl die These nicht unstrittig ist, da unklar ist, wie genau der Begriff der intuitiven Berechenbarkeit formal spezifiziert werden kann, wird sie in großen Teilen der KI-Forschung zugrunde gelegt. Wenn ihre Wahrheit angenommen wird, wenn also angenommen wird, dass die spezifisch algorithmische Umwandlung formaler Symbole in neue Symbole den Kern intuitiver Berechenbarkeit ausmacht – einem bestimmten Wert x wird ein neuer Wert f(x) zugewiesen – dann folgt, dass eine Turing-Maschine alles berechnen kann, was ein Mensch intuitiv berechnen kann: „Even though the Turing machine has only a handful of commands and proccesses only one bit at a time, it can compute anything that any computer can compute. Another way to say this is that any machine that is ‚Turing complete’ (that is, that has the equivalent capabilities to a Turing machine) can compute any algorithm (any procedure that we can define)” (Kurzweil, 2012, 186).
Obwohl der spezifizierte Begriff der Turing-Maschine der Begriff einer abstrakten Maschine ist, spezifiziert er als solcher die funktionalen Bedingungen, denen eine ingenieurstechnisch konstruierte physische Maschine als Annäherung an eine Turing-Maschine genügen muss, damit sie in der Lage ist, eigenständig Berechnungen durchzuführen. Dabei ist es unerheblich, mit welchem Material und auf welche Art und Weise eine Turing-Maschine konkret verwirklicht ist, solange das Konstrukt fähig ist, die formalen Bedingungen einer Turing-Maschine zu erfüllen (Kügler, 1995, 47f.). Da jede ingenieurstechnisch konstruierte Turing-Maschine ein Computer ist, folgt, dass jede künstliche Intelligenz, die auf die Funktionsweise eines Computers angewiesen ist, der prinzipiellen Funktionsweise einer Turing-Maschine unterliegt und an diese gebunden ist.
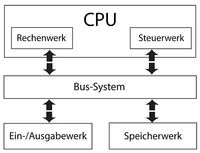
Die bis heute die ingenieurstechnische Konstruktion bestimmende Struktur von Computern geht dabei primär auf die Arbeiten von John von Neumann aus den Jahren um 1945 zurück. Die von Neumann entwickelte Architektur zur Konstruktion einer Turing-Maschine umfasst dabei die folgenden Komponenten:
- 1.Eine zentrale Recheneinheit, welche die logischen Operationen durchführt,
- 2.eine Kontrolleinheit, welche die Recheneinheit steuert,
- 3.einen Speicherort, auf dem die Software sowie die für die Berechnungen nötigen Daten gespeichert werden können,
- 4.ein Eingabe- und ein Ausgabewerk sowie
- 5.eine Steuerung (BUS), die die genannten Elemente miteinander verbindet (Kurzweil, 2012, 188; Alpaydin, 2016, 20).
Während die ersten nach diesem Prinzip konstruierten Computer raumgreifende Maschinen mit einer Länge von bis zu zehn Metern gewesen sind und wesentlich auf Vakuumröhren zur Repräsentation unterschiedlicher Systemzustände angewiesen waren (Röhrencomputer), hat sich durch die Erfindung von elektronischen Transistoren und integrierten Schaltkreisen in den 1950er Jahren die moderne elektronische Datenverarbeitung durchgesetzt und sowohl zu einer enormen Leistungssteigerung als auch zu einer erheblichen Verkleinerung der Computer geführt (Specht, 2019, 26). Die mit diesen Erfindungen in Gang gesetzte Kommerzialisierung der Computertechnologie hat in den Jahren seit 1960 zu einer exponentiellen Entwicklung der Leistungsfähigkeit der Computer geführt, die als das Mooresche Gesetz bekannt ist. Dieses geht davon aus, dass die technologische Entwicklung der Rechenleistung eines Computers im Schnitt alle 1,5 Jahre verdoppelt werden wird und diese Entwicklung erst dann an ein Ende gelangt, wenn der Zustand des Computroniums erreicht ist, der die Grenzen des physikalisch bestmöglichen Computers pro Materieeinheit bezeichnet: „As long as there is demand for more [computational resources], Moore’s law could continue to hold for many more decades before computronium is reached“ (Hutter, 2016, 200; zum Begriff des Computroniums: Bremermann, 1965).
2.1. Expertensysteme
In der KI-Forschung gibt es verschiedene Ansätze, wie die Hardware eines modernen Computers durch die Implementierung unterschiedlicher Algorithmen für KI-Systeme genutzt werden kann. Zu Beginn der Erforschung der Möglichkeiten der digitalen Datenverarbeitung wurden hauptsächlich sogenannte Expertensysteme konstruiert, die basierend auf durch den Menschen einprogrammiertem Wissen und deduktiven Schlussregeln zu einem bestimmten Input ein wohldefiniertes Spektrum an Antworten ausgeben können: „The concept of an expert system is that of a machine being able to reason about facts in a specific domain and to work in roughly the same way that an expert’s brain would work“ (Warwick, 2012, 32).
Die hinter der Entwicklung von Expertensystemen stehende Idee basiert im Kern auf der Einsicht, dass ein wesentliches Element der Struktur menschlichen Wissens darin besteht, dass es in der Form von logischen Implikationen darstellbar ist und es somit möglich ist, Bedingungen anzugeben, die spezifizieren, was im Falle des Vorliegens bestimmter Informationen logisch gültig geschlussfolgert werden kann: „An expert system is composed of a knowledge base and an inference engine. The knowledge is represented as a set of if-then rules, and the inference engine uses logical inference rules for deduction“ (Alpaydin, 2016, 50). Da diese Implikationsverhältnisse menschlichen Wissens prinzipiell algorithmisch einfach darzustellen und als regelbasierte Symbolverarbeitung zu programmieren sind, können Expertensysteme genutzt werden, um basierend auf der Eingabe einer bestimmten Information zu errechnen, was aus dieser Eingabe vor dem Hintergrund der algorithmisierten Implikationsverhältnisse folgt oder welcher Output welchen Input voraussetzt. Wenn in der Software beispielsweise festgelegt ist, dass Wenn A, dann B und A als Wert eingegeben wird, dann wird das Expertensystem B als Ausgabe anzeigen.
Basierend auf der Grundidee, dass menschliches Wissen in der Form von Konditionalen darstellbar ist, ist es prinzipiell möglich, ein Expertensystem zu konstruieren, welches über das gesamte konditionalisierbare Wissen der Menschheit verfügt. Da die Programmierung eines solchen allumfassenden Expertensystems aufgrund der komplexen Verhältnisse menschlicher Wissensverschränkungen die menschlichen Fähigkeiten aber de facto übersteigt, werden Expertensysteme primär für einzelne und überschaubarere Wissensbereiche, wie beispielsweise den der medizinischen Diagnostik, entwickelt. In diesen Bereichen skaliert die Leistungsfähigkeit und der Nutzen von Expertensystemen mit dem einprogrammierten Wissen der jeweiligen Experten (Warwick, 2012, 32-59).
2.2. Künstlich Neuronale Netzwerke
Neben den Expertensystemen besteht der zweite Ansatz der KI-Forschung in der Entwicklung von sogenannten künstlichen neuronalen Netzwerken (KNN). Der Begriff des künstlichen neuronalen Netzwerkes bezeichnet die algorithmische Verwendung eines Computers, die sich an der Verarbeitung elektrischer Signale in einem biologischen Gehirn orientiert: „An artificial neural network is a computer program inspired by certain presumed organizational principles of a real neural network“ (Kaplan, 2016, 28).
Das entscheidende Merkmal des Gehirns in Bezug auf die Konstruktion von künstlichen neuronalen Netzwerken besteht dabei darin, dass Informationen im Gehirn nicht seriell an einem zentralen Ort verarbeitet werden, sondern parallel und dezentral durch die Zustände der einzelnen Neuronen, die das gesamte neuronale Netzwerk (= Gehirn) konstituieren: Wie und ob bestimmte Neuronen im Gehirn reagieren, hängt im Allgemeinen nicht nur davon ab, auf welche Art und Weise sie mit den ihnen vorgelagerten Neuronen verbunden sind, sondern im Besonderen auch davon, ob der Zustand der vorgelagerten Neuronen aufgrund ihres Inputs einen bestimmen Schwellenwert überschreitet, der dazu führt, dass das Neuron aktiviert wird und somit erst Informationen an die verbundenen Neuronen weitergibt.
Dieses Verhalten der Neuronen im Gehirn hat in der KI-Forschung den Begriff des künstlichen Neurons inspiriert: Ein künstliches Neuron ist zunächst eine bestimmte mathematische Funktion, die einer reellen Zahl (Input, Argument) eine reelle Zahl zuordnet (Output, Argumentwert). Das Argument dieser Funktion ist dabei bereits das Ergebnis einer mathematischen Operation, die verschiedene Inputs beispielsweise durch Multiplikation unterschiedlich gewichtet hat. Ein künstliches Neuron ist also eine mathematische Funktion, die einem aus gewichteten Faktoren bestehenden Input in der Form einer reellen Zahl einen Output in der Form einer reellen Zahl zuordnet (Netzwert). Durch die unterschiedliche mathematische Gewichtung des Inputs eines künstlichen Neurons wird die im menschlichen Gehirn vorhandene unterschiedlich starke synaptische Verbindung einzelner Neuronen mathematisch nachgeahmt: Eine stärkere synaptische Verbindung wird mathematisch durch eine höhere Gewichtung des entsprechenden Faktors dargestellt und entspricht somit den exzitatorischen Verbindungen im Gehirn, während eine negative Gewichtung die inhibitorischen Verbindungen repräsentiert und somit für den Fall steht, dass die Aktivität eines Neurons die Aktivität der folgenden Neuronen hemmt. Um die Aktivierung eines Neurons im menschlichen Gehirn nachzubilden, werden in der KI-Forschung darüber hinaus bestimmte Argumentwerte einer Funktion als Aktivierungen des künstlichen Neurons verstanden, die dem Feuern von Neuronen im Gehirn entsprechen: Wenn das künstliche Neuron einen Wert in einem spezifizierten Intervall ausgibt, wird es als aktiviert betrachtet und sein Argumentwert wird Teil des wiederum gewichteten Inputs des im Netzwerk nachgelagerten künstlichen Neurons: „During operation, each neuron sums up the activations from all the neurons that make a synapse with it, weighted by their synaptic weights, and if the total activation is larger than a threshold value, the neuron ‚fires‘ and its ouput coresponds to the value of this activation; otherwise the neuron is silent. If the neurons fires, it sends its activation value in turn down to all the neurons with which it makes a synpase” (Alpaydin, 2016, 87). Künstliche Neuronen können dabei je nach nicht-linearer Aktivierungsfunktion unterschiedlich stark aktiviert sein: Während der Argumentwert f(x)=1 beispielsweise eine volle Aktivierung bedeuten kann, kann ein Argumentwert f(x)= 0,5 als eine schwache Aktivierung verstanden werden.
Ein künstlich neuronales Netzwerk ist ein Netzwerk künstlicher Neuronen und somit eine aus zahleichen mathematischen Teilfunktionen bestehende komplexe mathematische Funktion, die als Ganze betrachtet einem mathematisch gewichteten Input einen mathematisch gewichteten Output zuordnet. Ein KNN ist also kein physischer Nachbau eines menschlichen Gehirns mittels elektronischer Komponenten, sondern basiert auf der Idee, dass eine von Neumann-Architektur so verwendet werden kann, dass die Informationsverarbeitung anhand einzelner und miteinander verschachtelter Algorithmen (Funktionen) dem Modell des neuronalen Netzwerks des Gehirns entspricht: „Artificial neural networks are made up of many interconnected units, each one capable of computing only one thing“ (Boden, 2018, 69).
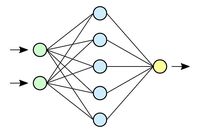
In der Regel wird ein einfaches KNN als feed-forward Netzwerk so konstruiert, dass es Informationen nur in eine Richtung weitergibt und es zwischen der Ebene (Layer) des Inputs und der Ebene des Outputs weitere Ebenen der Informationsverarbeitung gibt, die einander nachgeordnet sind und jeweils aus einzelnen künstlichen Neuronen, also den einzelnen mathematischen Funktionen, bestehen. Diese Ebenen eines KNN sind dabei weder mit dem Input des Systems noch mit dem Output des Systems unmittelbar verbunden, weswegen sie als hidden layer bezeichnet werden. Jedes künstliche Neuron jeder Ebene eines KNN beeinflusst, welchen Wert die mit ihm verbundenen und nachgelagerten Ebenen ausgeben. In einem KNN wird der Output des Programms also dadurch bestimmt, wie der gewichtete Input der ersten Ebene im System auf den einzelnen Ebenen aufgrund der jeweiligen Gewichtungen der Argumentwerte weitergegeben und berechnet wird. Dadurch ist impliziert, dass der Output eines KNNs durch den Aufbau und die Struktur des gesamten KNNs bestimmt wird.
Aufgrund der spezifischen Art der Informationsverarbeitung künstlich neuronaler Netzwerke sind sie in der Lage, Muster in Datenmengen, die als Input verwendet werden, zu erkennen. Dazu muss, je nach Zweck, ein KNN so konstruiert werden, dass künstliche Neuronen der Eingangsebene auf Merkmale der Datenmenge so reagieren, dass sie im Falle ihrer Aktivierung bestimmte künstliche Neuronen auf den nachgelagerten Ebenen aktivieren, die sich jeweils als spezifischere und gewichtete Kategorisierungen des Resultats der neuronalen Aktivierung auf der vorgelagerten Ebene verstehen lassen. Dieser Prozess wird je nach Netzwerk solange unter Einbezug weiterer Ebenen wiederholt, bis die künstlichen Neuronen der Ebene des Outputs auf eine bestimmte Art und Weise aktiviert werden, die semantisch als das Anzeigen eines bestimmten Musters gedeutet wird. Während also der Input eines KNN den künstlichen Neuronen der Eingangsebene bestimmte reelle Zahlen vorgibt, werden diese reellen Zahlen durch die unterschiedlichen mathematischen Funktionen der verschiedenen Ebenen solange umgewandelt, bis am Ende wieder eine reelle Zahl steht, die je nach System so interpretiert wird, dass sie das Vorliegen eines bestimmten Musters in der Ausgangsdatenbasis anzeigt. So kann ein KNN beispielsweise genutzt werden, um Bilder von Tieren zu kategorisieren: Aufgrund des Inputs auf der Eingangsebene erkennt das KNN zunächst verschiedene Helligkeitsgrade verschiedener Pixel, um je nach Aktivierung diese Helligkeitsgrade auf der nächsten Ebene verschiedenen geometrischen Formen zuzuordnen (Linie, Kreis etc.), die wiederum auf der nächsten Ebene verschiedenen Körperteilen und auf der finalen Ebene dann bestimmten Tierarten zugeordnet werden können (Churchland, 2000, 57-96; Specht, 2019, 226-229; Alpaydin, 2016, 99f.).
2.3. Maschinelles Lernen
Künstliche neuronale Netzwerke als Methode der Datenverarbeitung verfügen über ein an die Funktionsweise des menschlichen Gehirns angelehntes Merkmal, das ihre Leistungsfähigkeit und ihr potentielles Einsatzgebiet entscheidend erweitert: Analog dazu, dass sich im menschlichen Gehirn die Verbindungen zwischen den einzelnen Neuronen verändern können, können auch in einem künstlichen neuronalen Netzwerk die Verbindungen zwischen den Neuronen der unterschiedlichen Ebenen durch eine Veränderung der mathematischen Gewichtung des jeweiligen neuronalen In- und Outputs verändert werden, was dazu führt, dass sich die Informationsverarbeitung im gesamten Netzwerk verändert und derselbe Input im System nach der Veränderung zu einem anderen Output führt. Für dieses entscheidende Merkmal künstlicher neuronaler Netzwerke hat sich in der Debatte der Begriff des maschinellen Lernens machine learning eingebürgert. Maschinelles Lernen ermöglicht es, künstliche neuronale Netzwerke so zu trainieren, dass sie ihr Verhalten an die Datenlage und ihren jeweiligen Zweck flexibel anpassen können und in diesem Sinne in der Lage sind, aus vergangenem Verhalten zu lernen, um zukünftiges Verhalten zu optimieren. In der Forschung haben sich derzeit drei verschiedene Zugänge maschinellen Lernens als besonders vielversprechend erwiesen: das überwachte, das unüberwachte und das Reinforcement-Learning.
Im überwachten Lernen wird zunächst ein KNN mit einer bestimmten Aufgabe konstruiert, die beispielsweise darin bestehen kann, Katzen auf Bildern zu erkennen. Die mathematischen Gewichtungen der einzelnen Faktoren im Netzwerk werden dabei zu Beginn entweder zufälligerweise oder anhand spezifischer Erfahrungswerte gewählt. Im Anschluss daran werden dem KNN Bilder von Katzen und Nicht-Katzen gezeigt. Je nachdem, ob das KNN Katzenbilder als Bilder von Katzen sowie Bilder, die keine Katzen zeigen, als Bilder von Nicht-Katzen klassifiziert, werden die mathematischen Gewichtungen im System verändert, um die Wahrscheinlichkeit einer erfolgreichen Identifikation von Katzen zu erhöhen: „In supervised learning, the programmer ‚trains‘ the system by defining a set of desired outcomes for a range of inputs [...], and providing continual feedback about whether it has achieved them“ (Boden, 2018, 40). Da dieser Prozess der Adjustierung der komplexen Struktur eines KNN in den meisten Fällen menschliches Verstehen übersteigt, wird die Adjustierung in der Regel selbst von einem Algorithmus – dem sogenannten backpropagation algorithm – durchgeführt. Dieser Algorithmus rechnet basierend auf den auf der Outputebene angezeigten reellen Zahlen des Systems zurück, welche Verbindungen und Gewichtungen im System verändert werden müssen, um in erneuten Durchläufen mit möglichst hohem Erwartungswert das korrekte Ergebnis zu liefern und zu vermeiden, dass bereits korrekte Identifikationen zu Fehlidentifikationen werden: „[This] algorithm traces responsibility back from the output layer into the hidden layers, identifying the individual units that need to be adapted“ (Boden, 2018, 77). Im überwachten Lernen wird ein KNN also bei der Aufgabe, die es erfüllen soll, dadurch unterstützt, dass der Mensch die Entscheidungen des Systems kontrolliert und es mit Hilfe weiterer Algorithmen so verändert, dass es lernt, seine Aufgabe immer besser zu erfüllen (Alpaydin, 2016, 38-50).
Beim unüberwachten Lernen wird dem KNN keine spezifische Aufgabe gegeben, außer derjenigen, dass Strukturen und Muster erkannt werden sollen. Im unüberwachten Lernen analysiert das KNN, welche Eigenschaften einer Datenmenge auf statistisch relevante Art und Weise miteinander korrelieren und kann daher die Wahrscheinlichkeit angeben, mit der ein Merkmal A mit einem Merkmal B korreliert, wobei vorausgesetzt wird, dass Merkmale einer Datenmenge, die in der Vergangenheit gemeinsam aufgetreten sind, auch in Zukunft gemeinsam auftreten werden: „The aim in unsupervised learning is to find the regularities in the input, to see what normally happens. There is a structure to the input space such that certain patterns occur more often than others, and we want to see what generally happens and what does not” (Alpaydin, 2016, 111). Damit ein im Modus des unüberwachten Lernens betriebenes KNN zu statistisch belastbaren Schlussfolgerungen über die Wahrscheinlichkeit der Korrelation bestimmter Merkmale in spezifischen Datenmengen kommen kann, ist es notwendig, möglichst viele unterschiedliche Daten zu analysieren (siehe auch → Massenmedien
Im Reinforcement-Learning besteht das Ziel des KNN nicht primär in der Datenanalyse, sondern in der Entwicklung von Handlungsstrategien angesichts einer flexiblen und unvollständigen Datenlage. In Reinfocement-Systemen wird daher auch meist von einem Handlungsagenten (agent) gesprochen, der analog zu Tieren Entscheidungen trifft. Durch positive Verstärkung wird ein KNN daraufhin trainiert, dass es optimale Handlungsstrategien entwickelt: „Dabei bekommt das System keine Daten, die es sortieren soll, sondern lernt durch Versuch und Irrtum eine Handlungsstrategie. Bringt eine Entscheidung das System seinem Ziel näher, bekommt es eine elektronische ‚Belohnung‘. Im Laufe des Lernprozesses optimiert das System seinen Belohnungswert und lernt so eine Strategie“ (Lenzen, 2020, 41f.). Das Reinforcement-Learning ermöglicht es einem KI-Agenten beispielsweise, Bewegungsabläufe zu lernen oder erfolgreiche Spielstrategien zu entwickeln (Bauckhage, 2018). Ein Vorteil des Reinforcement-Learnings besteht darin, dass nicht alle möglichen Situationen, in die der KI-Agent geraten kann, im Vorhinein programmiert werden müssen: „If the system can learn and adapt to such changes, the system designer need not foresee and provide solutions for all possible situations” (Alpaydin, 2016, 17). Ein weiterer Vorteil besteht darin, dass ein KNN auch lernen kann, welche Strategien im Falle unvollständiger Informationen erfolgsversprechend sind.
2.4. Expertensysteme und Künstliche Neuronale Netzwerke
Expertensysteme und künstliche neuronale Netzwerke sind zwei verschiedene Möglichkeiten, wie Informationen mit Hilfe eines Computers algorithmisch verarbeitet werden können: „[They] have been developed independently as computing tools capable of solving problems which require ‚intelligence‘“ (Kurzyn, 1993, 222).
Eine Stärke von Expertensystemen besteht darin, dass sie anhand der im System definierten Schlussregeln berechnen können, was aus dem Input geschlussfolgert werden kann und welche Bedingungen für einen bestimmten Output gegeben sein müssen. Expertensysteme betrachten menschliches Wissen insofern es bereits in konditionalisierbarer und logisch handhabbarer Form vorliegt. Eine Schwäche der Expertensysteme besteht darin, dass sie in der Regel vom Menschen aufwendig programmiert werden müssen und ohne eine weitere Änderung ihrer Programmierung statische Systeme der Informationsverarbeitung sind, die nur für ein bestimmtes Wissensgebiet eingesetzt werden können. (Siehe auch → Kognitive Linguistik, Semantik
Eine Stärke von künstlich neuronalen Netzwerken besteht darin, dass sie sowohl in der Lage sind, allgemeine Muster und Strukturen in großen Datenmengen zu erkennen als auch über die Fähigkeit verfügen, durch die Veränderung ihrer inneren Struktur zu lernen. Sie schreiten in der Regel induktiv aufgrund der unterschiedlichen Gewichtungen des Inputs vom Besonderen zum Allgemeinen voran und können damit Aufgaben übernehmen, die ein Expertensystem nicht erfüllen kann. Im Unterschied zu einem Expertensystem muss ein KNN nicht von Anfang an in der Lage sein, seine Aufgabe effizient zu lösen, da es lernen kann, wie die Aufgabe im Rahmen seiner Möglichkeiten möglichst effizient erfüllt werden kann. Eine Schwäche künstlich neuronaler Netzwerke im Vergleich zu den Expertensystemen besteht darin, dass sie sehr große Datenmengen voraussetzen, um erfolgreich trainiert werden zu können. Darüber hinaus können sie oft keine Erklärungen bereitstellen, die ihre Resultate rational rechtfertigen. Während innerhalb eines Expertensystems die Erklärungen als Schlussregeln einprogrammiert und prinzipiell nachvollziehbar sind, zeigt ein KNN seine Ergebnisse nur als Wahrscheinlichkeiten vor dem Hintergrund der gesamten Struktur des KNNs an, was es schwieriger gestaltet, seine Entscheidungsregeln zu identifizieren. Wie Lenzen (2020, 76) es formuliert: „[D]ie lernenden Algorithmen liefern Korrelationen, keine Erklärungen. In der Wissenschaftstheorie wird derzeit diskutiert, ob wir gerade eine grundlegende Veränderung in der Wissenschaft erleben: weg von den erklärenden Theorien hin zu aus großen Datenmengen gelernten, aber letztlich nicht verstandenen Zusammenhängen“ (siehe auch Clark, 2005).
Den Stärken und Schwächen von Expertensystemen und künstlichen neuronalen Netzwerken entsprechen unterschiedliche Einsatzgebiete: „In general, symbolic reasoning is more appropriate for problems that require abstract reasoning, while machine learning is better for situations that require sensory perception or extracting patterns from noisy data“ (Kaplan, 2016, 36). Obwohl Expertensysteme und KNNs unterschiedliche Prozesse der Informationsverarbeitung sind – Expertensysteme haben ihren Fokus auf logischer Deduktion und KNNs auf induktiver Wahrscheinlichkeit –, spricht prinzipiell nichts dagegen, ein System zu entwickeln, dass beide Ansätze kombiniert (d‘Avila Garcez, 2015; Boden, 2018, 86-89). Beide Arten der Informationsverarbeitung repräsentieren letztlich unterschiedliche Aspekte intelligenten Verhaltens: Expertensysteme setzen die Wahrheit der algorithmisch spezifizierten Konditionale a priori voraus und sind in der Lage, logische Schlussfolgerungen aus dieser Datenmenge zu generieren. Sie entsprechen der menschlichen Praxis des logischen Schließens, welche Wissensansprüche unabhängig von Fragen ihrer Genese als gesetzt voraussetzt und an den logischen Implikationen dieser Wissensansprüche interessiert ist. Künstliche neuronale Netzwerke hingegen analysieren große Datenmengen im gewissen Sinne a posteriori, um einerseits entscheiden zu können, wie der Input unter Verwendung eines bestimmten Begriffsschemas klassifiziert werden kann und andererseits entdecken zu können, welche statistisch relevanten Korrelationen in der Datenmenge vorliegen. Damit lassen sie sich in ein analoges Verhältnis zu menschlichen Praktiken der auf der Sinneserfahrung basierenden Genese von Wissensansprüchen verstehen, deren Ziel es ist, bestehende Zusammenhänge in der Welt zu erkennen, die dann eventuell als konditionalisierte Wissensansprüche verwendet werden können.
2.5. Embodied und disembodied künstliche Intelligenz
Aufgrund ihrer Struktur repräsentieren Expertensysteme paradigmatisch denjenigen Aspekt intelligenten Verhaltes, der Intelligenz als Fähigkeit zu logischem Schließen betrachtet, die unabhängig davon ist, ob das System über eine bestimmte körperliche Präsenz verfügt, die es mit seiner Umgebung in ein kausales Verhältnis setzt: „The idea that intelligence or reason is a quality, one that can be isolated from the physical body and captured in a formal system represents the earliest and, until the 1980s, most common, approach to creating a human image in the computer, an approach generally referred to as symbolic AI“ (Herzfeld, 2002, 35). Mit der Entwicklung von lernfähigen künstlichen neuronalen Netzwerken, die große Datenmengen auf statistisch relevante Korrelationen untersuchen, hat sich neben den Expertensystemen eine weitere Form künstlich intelligenter Systeme etabliert, die unabhängig ihrer körperlichen Präsenz in der Welt auf das reine Analysieren von Informationen spezialisiert ist. Obwohl jede künstliche Intelligenz auf die Existenz eines Computers angewiesen ist, der aus physikalischer Materie besteht, werden Formen künstlicher Intelligenz, die über keinen für ihre Funktion wesentlichen Körper verfügen, der in kausaler Wechselwirkung mit seiner Umwelt steht, als disembodied bezeichnet.
Im Unterschied zur disembodied KI bezeichnet der Begriff der embodied KI eine künstliche Intelligenz, die über eine körperliche Präsenz verfügt und in kausaler Wechselwirkung mit ihrer Umwelt steht. Die entscheidende Motivation hinter der Entwicklung von embodied KI besteht in der Erkenntnis, dass das Vermögen zu abstraktem Schlussfolgern im engen Zusammenhang damit steht, ob sich das jeweilige System mittels eines Körpers in Interaktion mit einer flexiblen Umwelt befindet und aus den Reaktionen der Umwelt und des eigenen Körpers lernen kann: „What is of considerable interest now, and will be even more so, is the effect of the body on the intellectual abilitites of that body’s brain. Ongoing research aims at realising an AI system in a body – embodiment – so it can experience the world, whether it will be the real version of the world or a virtual or even simulated world“ (Warwick, 2012, 10). Das wesentliche Merkmal von embodied KI besteht darin, dass sie über eine sensorische Erfassung ihrer Umwelt verfügt und die mittels der Sensoren gewonnenen Daten zur Steuerung der Maschine verwendet, um auf diese Weise ihren Zweck zu erfüllen. Eine KI-gesteuerte Maschine wird dabei als Roboter bezeichnet und ein Roboter, der sich an der Physiologie des Menschen orientiert, als ein Android (siehe auch → Transhumanismus
3. Künstliche Intelligenz und Superintelligenz
Da die Leistungen gegenwärtiger KI-Systeme bereits in vielen Bereichen das Potential des Menschen zur Lösung der gewählten Aufgaben übertreffen und maschinelles Lernen künstlich intelligenten Systemen ermöglicht, effizient und schnell das Lösen neuer Aufgaben zu bewerkstelligen, stellt sich die Frage nach den Grenzen der Möglichkeiten künstlich intelligenter Systeme. Wenn die menschliche Intelligenz als Paradigma einer allgemeinen Intelligenz betrachtet wird, die nicht nur in der Lage ist, ganz unterschiedliche kognitive Aufgaben zu übernehmen, sondern sich auch aufgrund des menschlichen Körpers eigenständig und zielgerichtet in der Welt bewegen kann, führt dies zur Frage, ob der Mensch fähig ist, eine künstliche allgemeine Intelligenz (artificial general intelligence) zu konstruieren, die wie der Mensch über allgemeine Intelligenz verfügt und in der Lage ist, sich eigene Ziele ihres Handelns zu setzen (siehe auch → Digitalisierung
Ein zentrales Argument für diese Möglichkeit basiert auf der Prämisse, dass es prinzipiell möglich ist, ein funktionales Äquivalent des für seine Intelligenz verantwortlichen Gehirns des Menschen mit Hilfe eines lernfähigen künstlichen neuronalen Netzwerkes zu erschaffen. Wenn es gelingt, so die Annahme, die strukturelle Funktionsweise des Gehirns mit einem KNN zu simulieren (whole brain emulation), dann wäre eo ipso eine künstliche allgemeine Intelligenz geschaffen, die über die gleichen Vermögen verfügt, wie die menschliche Intelligenz. Ein zentrales Argument gegen die Möglichkeit der Entwicklung einer solchen an der menschlichen Intelligenz orientierten künstlichen allgemeinen Intelligenz weist hingegen darauf hin, dass die entscheidenden Faktoren der Konstitution menschlicher Intelligenz unmittelbar in dem konkreten biochemischen Aufbau des menschlichen Gehirns zu gründen scheinen und ein funktionales Äquivalent, das letzten Endes eine komplexe Turing-Maschine auf einer von Neumann-Architektur wäre, daher ebenso wenig über die allgemeine Intelligenz des Menschen verfügen könne, wie eine Simulation von Wasser die Eigenschaften von H2O ihr Eigen nennen kann.
Da sich in der KI-Debatte gezeigt hat, dass die menschliche allgemeine Intelligenz, die sich im Laufe der Evolution entwickelt hat, nur eine mögliche Art und Weise ist, wie eine allgemeine Intelligenz verwirklicht sein kann, werden jenseits der Debatte zur digitalen Nachbildung des menschlichen Gehirns anderweitige theoretische Möglichkeiten diskutiert, eine künstliche allgemeine Intelligenz zu konstruieren. Diese Ansätze basieren beispielsweise auf der Annahme, dass Algorithmen genutzt werden können, die es ermöglichen, KNNs einem Prozess zu unterwerfen, der analog zur biologischen Evolution verstanden werden kann (artificial evolution): Durch Algorithmen, die zufälligerweise den Aufbau und die Gewichtung eines künstlichen neuronalen Netzwerkes verändern, kann herausgefunden werden, ob seine Problemlösungsfähigkeit (= Intelligenz) steigt und es könnte prinzipiell möglich sein, durch die Aussortierung ungeeigneter Kandidaten die weitere evolutionäre Entwicklung der vielsprechenden KNNs so zu regulieren, dass ihre Intelligenz das menschliche Niveau erreicht (Chalmers, 2016). Unabhängig von den einzelnen Ansätzen, eine künstlich allgemeine Intelligenz zu entwickeln, scheint es angesichts der Tatsache, dass intelligentes Verhalten ganz unterschiedlich physisch realisiert sein kann, prinzipiell möglich zu sein, eine künstliche allgemeine Intelligenz zu konstruieren, deren Verhalten als intelligent im Sinne menschlicher Intelligenz beschrieben werden kann. Ein Argument gegen diese These müsste zeigen, dass es prinzipiell naturgesetzlich unmöglich ist, dass allgemeine Intelligenz anders als durch einen blinden evolutionären Prozess entstehen kann.
Wenn es prinzipiell möglich ist, eine künstliche allgemeine Intelligenz zu erschaffen, dann scheint es auch prinzipiell möglich zu sein, dass die Entwicklung im Bereich der KI zur Entwicklung einer sogenannten Superintelligenz (superintelligence, singularity) führen könnte. Die Idee der Superintelligenz wurde von Irvin John Good in die Debatte eingeführt: “Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines; there would then unquestionably be an ‘intelligence explosion,’ and the intelligence of man would be left far behind. Thus the first ultraintelligent machine is the last invention that man need ever make, provided that the machine is docile enough to tell us how to keep it under control” (Good, 1965, 33).
Der Begriff der Superintelligenz bezeichnet also eine künstliche allgemeine Intelligenz, die der menschlichen Intelligenz in den meisten Bereichen extrem weit überlegen ist und daher zu Erkenntnissen und Problemlösungen gelangen kann, die der Mensch nicht länger rational nachvollziehen kann. Die Argumente, die für die prinzipielle Möglichkeit einer Superintelligenz sprechen, gehen davon aus, dass der Mensch in der Lage ist, eine künstliche allgemeine Intelligenz zu erschaffen. Da sich die so erschaffene künstliche allgemeine Intelligenz von der menschlichen Intelligenz bereits dadurch unterscheiden würde, dass sie nicht den biochemischen Restriktionen menschlicher Intelligenz unterliegt, und aufgrund der technologischen Fortschritte digitaler Systeme bereits wesentlich schneller und effizienter voranschreiten könnte als der Mensch, so das Argument, ist davon auszugehen, dass diese künstliche allgemeine Intelligenz in der Lage ist, den Prozess, auf den sich der Mensch zu ihrer Entwicklung gestützt hat, so zu verbessern, dass dadurch eine leicht verbesserte Version der ursprünglichen künstlichen allgemeinen Intelligenz erschaffen werden kann. Wenn dies aber der Fall ist, so das Argument, dann wird die verbesserte Version der künstlich allgemeinen Intelligenz erneut zu einer noch weiter verbesserten künstlichen allgemeinen Intelligenz und somit unweigerlich zur Erschaffung einer Superintelligenz führen. Wenn also eine künstliche allgemeine Intelligenz prinzipiell möglich ist, so das Argument, dann ist auch eine Superintelligenz im Bereich des Möglichen (Bostrom, 2014; Awret, 2016; Karger, 2020; Schneider, 2018).
Literaturverzeichnis
- Alpaydin, Ethem, Machine Learning, London 2016.
- Awret, Uziel (Hg.), The Singularity. Could artificial intelligence really out-think us (and would we want it to?), Exeter 2016.
- Bauckhage, Christian (Hg. u.a.), Kognitive Systeme und Robotik. Intelligente Datennutzung für autonome Systeme, in: Neugebauer, Reimund (Hg.), Digitalisierung. Schlüsseltechnologien für Wirtschaft und Gesellschaft, Berlin 2018, 239-260.
- Boden, Margaret A., Introduction, in: Boden, Margaret A. (Hg.), The Philosophy of Artificial Intelligence, Oxford 2005, 1-21.
- Boden, Margaret A., Artificial Intelligence. A Very Short Introduction, Oxford 2018.
- Bostrom, Nick, Superintelligence, Oxford 2014.
- Brand, Lukas, Künstliche Tugend. Roboter als moralische Akteure, Regensburg 2018.
- Bremermann, Hans J., Quantum Noise and Information, in: Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability. Berkeley, California 1965, 15-20.
- Chalmers, David, The Singularity. A Philosophical Analysis, in: Awret, Uziel (Hg.), The Singularity. Could artificial intelligence really out-think us (and would we want it to?), Exeter 2016, 11-69.
- Churchland, Paul M., The Engine of Reason, the Seat of the Soul. A philosophical journey into the brain, Cambridge/Massachusetts 2000.
- Clark, Andy, Connectionism, Competence, and Explanation, in: Boden, Margaret A. (Hg.), The Philosophy of Artificial Intelligence, Oxford 2005, 281-308.
- d‘Avila Garcez, Artur (Hg. u.a.), Neural-Symbolic Learning and Reasoning: Contributions and Challenges, in: Papers from the 2015 AAAI Spring Symposium, California 2015. Online unter: https://www.aaai.org/ocs/index.php/SSS/SSS15/paper/viewFile/10281/10029
, abgerufen am 12.06.2021. - Good, Irvin J., Speculations Concerning the First Ultraintelligent Machine, in: Alt, Franz L./Rubinoff, Morris (Hg.), Advances in Computers, New York 1965, 31-88.
- Göcke, Benedikt P., Could Artificial General Intelligence be an End-in-Itself, in: Göcke, Benedikt P./Rosenthal-von der Pütten, Astrid (Hg.), Artificial Intelligence. Reflections on Philosophy, Theology, and the Social Sciences, Leiden 2020, 221-240.
- Herrick, James A., Visions of Technological Transcendence. Human Enhancement and the Rhetoric of the Future, South Carolina 2017.
- Herzfeld, Noreen L., In Our Image. Artificial Intelligence and the Human Spirit, Minneapolis 2002.
- Hutter, Marcus, Can Intelligence explode?, in: Awret, Uziel (Hg.), The Singularity. Could artificial intelligence really out-think us (and would we want it to?), Exeter 2016, 196-219.
- Kaplan, Jerry, Artificial Intelligence. What Everyone Needs to Know, Oxford 2016.
- Karger, Kilian, Will Superintelligence take over? A Critical Reflection on the apparent and actual dangers of artificial intelligence, in: Göcke, Benedikt P./Rosenthal-von der Pütten, Astrid (Hg.), Artificial Intelligence. Reflections on Philosophy, Theology, and the Social Sciences, Leiden 2020, 87-104.
- Kurzweil, Ray, How To Create a Mind. The Secret of Human Thought Revealed, New York 2012.
- Kurzyn, Marian S., Expert Systems and Neural Networks: A Comparison, Clayton, Victoria 1993. Online unter: https://www.computer.org/csdl/pds/api/csdl/proceedings/download-article/12OmNz5apLv/pdf
, abgerufen am 24.06.2021. - Kügler, Peter, Vom Funktionieren zum Interpretieren, Frankfurt a. M. 1995.
- Legg, Shane/Hutter, Marcus, A Collection of definitions of intelligence, in: Goertzel, Ben/Wang, Pei (Hg.), Advances in Artificial General Intelligence: Concepts, Architectures and Algorithms. Amsterdam 2007, 17-24.
- Lenzen, Manuela, Künstliche Intelligenz. Fakten, Chancen, Risiken, München 2020.
- Mainzer, Klaus, Künstliche Intelligenz – Wann übernehmen die Maschinen?, Berlin 2016.
- Russell, Stuart J./Norvig, Peter, Artificial Intelligence. A Modern Approach, Boston 2016.
- Schmidhuber, Jürgen, Philosophers & Futurists, Catch Up!, in: Awret, Uziel (Hg.), The Singularity. Could artificial intelligence really out-think us (and would we want it to?), Exeter 2016, 226-235.
- Schneider, Susan, Künstliche Intelligenz und die Zukunft der Menschheit, in: Göcke, Benedikt Paul/Meier-Hamidi, Frank (Hg.), Designobjekt Mensch. Der Transhumanismus auf dem Prüfstand, Freiburg i. Br./Herder 2018, 259-270.
- Specht, Philip, Die 50 wichtigsten Themen der Digitalisierung. Künstliche Intelligenz, Blockchain, Robotik, Virtual Reality und vieles mehr verständlich erklärt, München 2019.
- Tegmark, Max, Life 3.0. Being Human in the Age of Artificial Intelligence, New York 2016.
- Turing, Alan M., Computing Machinery and Intelligence, in: Mind, New Series 59 (1950) 236, 433-460.
- Warwick, Kevin, Artificial Intelligence. The Basics, London 2012.
Abbildungsverzeichnis
- Turing-Maschine. Aus: Wikipedia. Die freie Enzyklopädie ©CC BY-SA 3.0. Online unter: https://de.wikipedia.org/wiki/Turingmaschine#/media/Datei:Turingmaschine.svg, abgerufen am 25.06.2021.
- Von Neumann-Architektur. Aus: Wikipedia. Die freie Enzyklopädie ©Gemeinfrei. https://de.wikipedia.org/wiki/Von-Neumann-Architektur#/media/Datei:Von-Neumann_Architektur.svg, abgerufen am 25.06.2021.
- Künstliches Neuronales Netzwerk. Aus: Wikipedia. Die freie Enzyklopädie. Der Input der grünen Eingangsebene führt zu einer bestimmten Aktivierung des blauen hidden layers. Diese wiederum führt zu einer Aktivierung auf der gelben Outputebene. ©CC BY 1.0. https://de.wikipedia.org/wiki/Künstliches_neuronales_Netz#/media/Datei:Neural_network.svg, abgerufen am 25.06.2021.
PDF-Archiv
Alle Fassungen dieses Artikels ab Oktober 2017 als PDF-Archiv zum Download: